Linear Quadratic Gaussian Control
June 30, 2023
This post gives a gentle introduction to the control theory and linear quadratic Gaussian control.
Introduction
The subject of control theory is a dynamical system. Let denotes the state of the system, then
where is a function, describes the system. For example, a moving particle in a field may be described by its position and velocity, a 2-dimensional space, and the physics of the system determines . In general, determining is a hard physics problem which will not be the focus of this post. We will consider only linear systems, for which is a linear function, or we can simply write the system of equations as
where In reality, is almost never linear, so we linearize the system around the fixed points, i.e., where , so that we can approximate the system near the fixed points as a linear system with , the Jacobian.
To control the system, we assume that we have control “knobs” which affects the system linearly,
where . Here is completely determined by the physics of the control knobs, and it is fixed once the system is manufactured.
For linear closed-loop feedback control, we assume , where is the control law. Therefore, the system of equations becomes
The solution to this system of first-order ODE is
where is the spectral decomposition. The stability of the system is determined by the eigen-values of .
Linear Quadratic Gaussian
Linear Quadratic Regularizer
Linear Quadratic Regularizer assumes a quadratic cost with the form
where , and is the desired state.
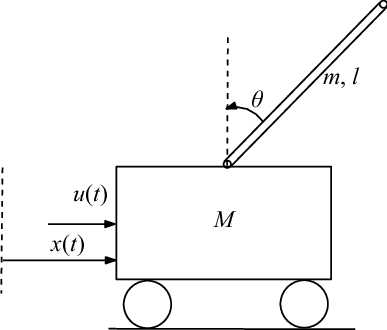 Figure 1. Inverted Cart Pole Problem.
Figure 1. Inverted Cart Pole Problem.
For example, consider a inverted cart pole problem, where the state space is . Consider the desired state , which is also a fixed point to linearize around. Assume there is no friction, then
We can define the cost matrices as
The Linear Quadratic Regularizer finds the optimal control law such that
is minimized as long as the system is controllable.
Kalman Filter
In reality, often we cannot measure the full state of the system. The Kalman Filter allows us to measure only a partial state, and recover an estimation of the full state together with the control input. Suppose the measured values are , where is a matrix and is a smaller vector. The Kalman Filter defines the Kalman Filter solves for the optimla Kalman Filter gain to estimate the state from , such that the estimate is updated according the following ODE:
where . Intuitively, the Kalman Filter is a closed-loop system for state estimation. Substitue in the actual dynamics
we have
Write , we have
Now similar to LQR, we can solve for an optimal .
The crucial reason for using the Kalman Filter is that we have disturbance to our system and noise to our sensor measurements ,
The Linear Quadratic Gaussian assumes that and are Gaussian to find the optimal and .
References
[1] Steve Brunton, Control Bootcamp, Videos