A Fault-Tolerant Distributed System with Raft
July 16, 2020
This post lays down the motivations and challenges for distributed systems and introduces an approach to fault-tolerant distributed systems using Raft.
Distributed Systems: Why and How
A distributed system is a cluster of networked computers working collectively. Why would we want distributed systems? One answer is: if one computer needs 20 hours to do some computing, then 20 computers may complete the job in one hour. Another answer is: if we just have a copy of data on one computer, it may fail, and we’d like to store multiple copies of data on different computers.
But achieving these goals isn’t easy. Without coordination, 20 computers may simply produce useless outputs which are a worse result than using a single computer. We want to achieve 3 essential goals when coordinating a cluster of computers:
- Performance: we’d like the performance to scale with the number of computers.
- Consistency: we’d like replicated data stored on different computers to stay consistent.
- Fault-tolerant: we’d like the system keeps to work when some computers fail or at least recover quickly.
On the performance side, MapReduce is one of the earliest programming models for distributed systems that enable high performance. For now, Spark is a very popular general-purpose cluster-computing framework, meaning that it’s able to utilize a distributed system to achieve high performance without the need to write programs in a certain model like map-reduce. Performance won’t be the focus of this post, instead, I’ll focus on consistency and fault-tolerance in a distributed system.
Fault-tolerance
Besides performance, one major reason to use a distributed system is to tolerate faults. If you only have one computer doing a job, what if it fails? You’ll have to restart again, and it may take a long time that is not acceptable. If you only have one computer storing some data, what if it fails? You’ll need to pray that someone can recover the computer.
We’ll be able to tolerate these faults if we have several replicated servers. If the major server fails, we will be able to use another replica to continuing the service.
Nevertheless, it’s not easy to replicate a machine. One straightforward method is to copy the entire state of one server and transfer it to other servers. However, this can be very challenging: (1) The state of the server is almost always constantly changing, and it is costly to transfer a large amount of data; (2) transfer via the network may be fragile and we can easily get some deprecated data, which means we need extra procedures to check data and potentially retry often.
Suppose we have a database server witch supports simple to get and put requests, and we want replicas of the data on the server on other computers. Consider this approach: rather than transfer the data once for a while, we can let every replicated server to function as the master server. As long as they receive the same requests and carry out the same operations, we can assure the data is consistent across servers. This is the idea behind state machine replication.
Now we can give a general description of a fault-tolerant service using state machine replication. A client starts a request and sends the request to the master server, the master server distributes the request to other replicated servers and wait for their acknowledgments, and the master server replies to the client once the master server gets enough acknowledgments. Note that here we don’t let the client send requests to all the servers, but let the master server distribute the request so that the underlying distributed implementation is abstracted from the client.
This general approach has many loopholes that demand further details. To proceed, we should see what kind of faults we need to deal with:
-
Some server may fail completely:
a. If the master server fails, and exactly one replicated server needs to realize that and step up as the master. Furthermore, when the original master recovers, we need to update it to the current state.
b. If a replicated server fails, we need to update it to the current state
-
The network connection may fail:
a. The client’s network fails so that it cannot connect to the servers, but we don’t need to deal with this situation
b. If the network fails and the master cannot connect some of the servers, we need to define the behaviors of the unconnected follower servers: should they wait or should one of them become the master? In the latter case, we will have two disconnected master, which gives rise to the split-brain problem.
Raft
We will focus on a specific algorithm that can provide fault-tolerant service for distributed systems, Raft. It is referred to as a consensus algorithm under a non-Byzantine scenario, which kind of means that there is no malicious server that tries to fool others and that we need to only deal with above non-malicious faults. Why consensus is relevant to building a fault-tolerant distributed system? Remember that we are using state machine replication approach to replicate our servers, so essentially we need to transfer the set of operations each server needs to apply to their states. The servers need to achieve consensus on the set of operations. It can be the set of requests from the clients, and it can be a set of any formats of commands.
The central idea of Raft is rather “democratic.” The valid set of operations is defined by a leader (master server) elected by a majority of the servers. The leader will be re-elected if the current leader fails. In general, Raft follows the procedure below:
- A leader (the master server) is elected if it receives a majority of votes among all servers.
- Each leader has an associated term number which increases monotonically for each new leader.
- A request from a client that contains an operation is sent only to the leader, and the leader distributes operations along with its term number to all the servers.
- When a majority of servers acknowledge the new operation, the leader applies the operation; it also updates its commit index which represents the last operation it has applied.
- The leader periodically sends our a heartbeat message to continue its leadership. The heartbeat message also contains information including the term number and its commit index for the followers to update their states.
- Each server keeps a list of entries called log, each entry containing an operation, and the term number when the entry is inserted.
- Each server has a timer with a which will be trigger within a random duration. Once the timer triggers, it runs for an election and asks other servers for votes.
- Whenever a server receives a message from another server (it may be a new entry, a heartbeat, or a request for vote), if the term number of the sender is at least as high as itself, it resets the timer. It also updates its term number if the sender of the message has a higher term number.
- If the request is a request for a vote, it grants the vote as long as:
- the candidate has the same term number;
- the candidate’s log is at least as long as the local log;
- the server has not voted for another candidate.
- If the request is to append new entries (sent from a leader):
- If commit index of the leader is higher than local commit index, update commit index and apply for all the entries before commit index.
- If the server finds conflicts between the leader’s log and its log, it replies to the leader and it will ultimately update its log to the leader’s log.
- If the request is a request for a vote, it grants the vote as long as:
There are many more details and small discrepancies involved in the procedure, and you should check out the paper for the most accurate description. Here are more observations for a better understanding of the concepts involved:
- term number can be understood as the version of a server, and it cannot become the leader if its version is outdated. This prevents a server that is disconnected for a while to mass-up other servers.
- log can be understood as a list of operations. Our goal is to keep the log consistent across all the servers so that any server can apply each operation following the sequence of the log and arrive at the same state. Inserting an operation into the log and actually applying an operation are separated events.
- commit index decides to which point in the log operation is applied (committed). It is assumed that an applied operation cannot be revoked. Therefore, it’s unsafe to apply an operation as soon as it is inserted since other servers never get the operation due to some failures.
- heartbeat is sent only by the leader (at least according to itself) to tell other servers that it is still alive. This enables other servers to detect failures of the leader and to run for election.
Now let’s make some key observations about how will Raft performs in response to the faults we lay down previously.
1a. The leader fails completely.
(1) If the client who sends very last entry before the leader fails to get an acknowledgment:
This means that a majority of the servers have received the new entry from the leader, otherwise the leader will not send back the acknowledgment. The servers who have not received the new entry cannot win an election, because the majority of the servers have a more complete log and will not vote for them. Therefore, a server that has received the last entry will win the election and the log kept consistent with what clients will expect. The new leader will update the outdated servers (including the previous leader when it becomes alive).
(2) If the client who sends very last entry before the leader fails does not get an acknowledgment:
The behavior can vary. A server that hasn’t got the new entry may be elected. In that case, the client will treat this as a failed request and retry.
1b. Some replicated servers fail completely.
The leader will keep them updated when they come back alive.
2b. Network fails and the master cannot connect some of the servers.
If the unconnected servers are a minority, they will simply stay unchanged until they reconnect to the leader since none of them can be elected.
If the unconnected servers are a majority, they will elect a new leader, and we will have the serious problem of split-brain. In effect, we now have two leaders and two disconnected clusters, each able to receive requests from different clients. Luckily, the previous leader along with its followers, Cluster A, will never apply any operations or reply to a client’s request since they are a minority, and the new leader along with its followers, Cluster B, will apply operations instead. When they reconnect, the previous leader will step down because it has a lower term number, and Cluster A will be synced according to Cluster B.
There are many trickier failures that I haven’t discussed, but are solved by Raft.
A framework of distributed service using Raft
Raft provides us a firm algorithm to achieve consensus about the set of operations, and we can now describe a framework to build a service on top of Raft.
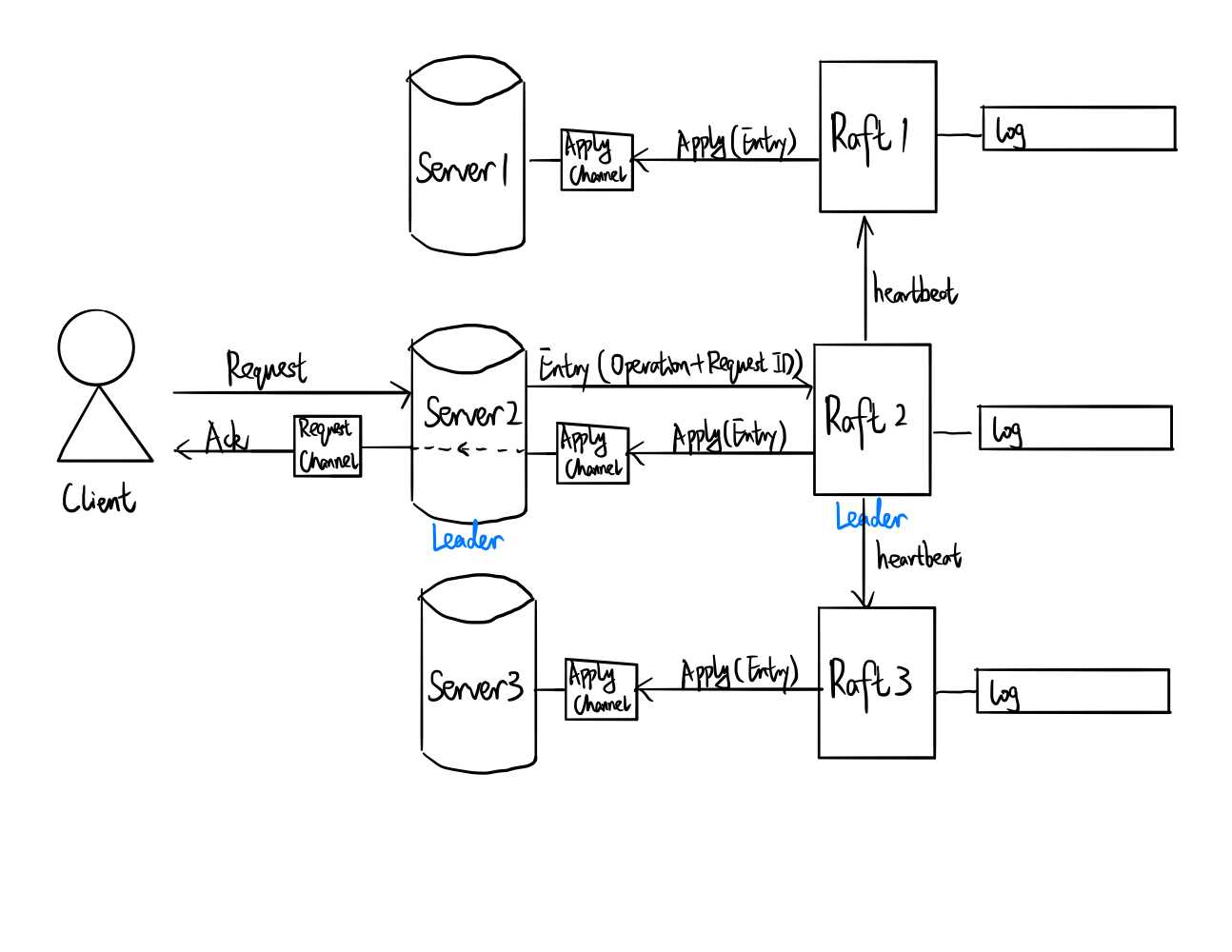 Figure 1. Distributed Service using Raft.
Figure 1. Distributed Service using Raft.
The idea is as follows:
- The service is provided by a cluster of Servers:
- Each Server has an associated Raft
- Servers don’t communicate with each other, but Rafts communicate constantly to reach consensus
- The leader among Servers associated with the leader among Rafts.
- A Server and its Raft communicates through a apply channel. When an entry is committed at Raft, the Raft sends a message via apply channel.
- Clients contact all Servers, but only send requests to the leader.
- Upon a request:
- The Client sends the request to the leader Server.
- The leader Server tags the request with a request ID, and sends an entry consisting of necessary operations for the request along with a unique request ID to its Raft. It also creates a channel associated with request ID and waits for a response.
- The leader Raft receives the entry and distributes it to other Rafts, waiting for a majority acknowledgment, and then applies via apply channel.
- Servers constantly listening to apply channel, and when a new apply message comes, they perform the operations. If there is an opening channel associated with request ID (meaning that a client is waiting for a response), it sends an acknowledgment through the channel.
- The leader Server receives the acknowledgment via the channel associated with request ID and responds to the client.
References
[1] Ongaro, Diego, and Ousterhout, John. In Search of an Understandable Consensus Algorithm (Extended Version).
[2] CS 6.824 at MIT, Distributed Systems, Spring 2020, Website