Big Data Message System
July 18, 2020
This post introduces a framework for a message system for big data built with Kafka+Flink+ElasticSearch and how do these tools work behind the scene.
Components of a Message System
An app today produces trillions of data that embeds enormous insights for the business executives, engineers, market analysts, etc. It is a non-trivial job to collect those data and effectively store them.
Let’s think about a particular scenario and a particular type of data: heartbeat. Heartbeat data is a periodic signal log sent by software (or hardware) to indicate its current state. For example, for a video streaming app, when a user plays a video, the app sends multiple heartbeats that include data like the user id, the session id, the app version, the video playing status (buffering, playing, pausing), etc. These are valuable information for engineers to debug the app and for product managers/data analysts to analyze user behavior and experience. A minimal viable product is as follows: the system transfers data from the app to a database which allows easy access to individual data via a user id.
For this minimal product, we still need three essential stages.
First of all, we need to decide where heartbeat data should be sent from the apps on a user’s machine. Presumably, we can directly send data to a database, but this has several disadvantages. (1) We may need to process data, and this happens most efficiently on a dedicated server via batch processing. (2) We don’t want a user’s app to directly connect to our backend database or a processing server. There is an even more important reason, which introduces Apache Kafka. We may want our data sent to not a single database, but multiple different ones with distinct usage. We may also have different sources generating different data other that heartbeat data. If we allow each of the data sources and targets to connect directly, we simply get a mass. Instead, data sources send data to a Kafka server, and other servers can contact the Kafka server for a particular type of data. The data sources are called producers, and the latter is called consumers.
As I mentioned, we may also want a server to process streaming data. This server is special in that we are facing millions of data per second, and we need a special processing paradigm to boost performance. This cannot be done by a normal single computer, but by a cluster of computers working in parallel. Apache Flink is a widely used streaming processing framework.
Finally, we need some type of database that provides fast access to particular heartbeat data. For this post, we will use ElasticSearch, which is commonly used as a search engine, and we will talk about how it works more in-depth.
Apache Kafka
The telephone needs a switching center to accept incoming calls and match them to callees. The Internet needs switches to accept incoming packages and send them the target receivers. In the world of big data, Kafka is the switching system. Kafka accepts data stream from multiple producers such as mobile apps, web pages, network-connected hardware, and allows multiple consumers to retrieve the data.
 Figure 1. Kafka. (Image source: Stéphane Maarek blog)
Figure 1. Kafka. (Image source: Stéphane Maarek blog)
Kafka’s Top-level Concepts
On the top abstraction level, consumers and producers interact with a Kafka server with the following essential interfaces.
-
Topic
A topic is a virtual group of data. A producer sends data to a particular topic or potentially multiple topics, while a consumer subscribes to a topic to retrieve data in this virtual group. In general, a topic contains messages of the same type, but it is flexible and accepts messages of multiple types (ultimately in bytes).
-
Partition
The data of a topic is stored in multiple partitions, which can be thought of as an array list. A producer decides which partition a message is sent to by assigning each message a key and defining a partitioning strategy. The default partitioning strategy is hashing, and the default behavior of not having a key is round-robin.
-
Offset
As mentioned, a partition is like an array list, and an offset indicates an index to the list.
-
Consumer Group
The consumers of a topic can be further divided into consumer groups. For example, the security engineering team wants log events from Kafka for security checks, and data engineers team wants the data same for data analysis. They may require different consumption rates and processing strategies of the data, and we will have two groups. Each partition of a topic will be subscribed by at most one consumer in a group at a time. If there are more partitions in a topic than the consumers in a group, each consumer can subscribe to more than one partition. The programmer can set the system to consumers from groupOffsets so that the group acts as a single consumer and process data sequentially.
Kafka’s Architecture
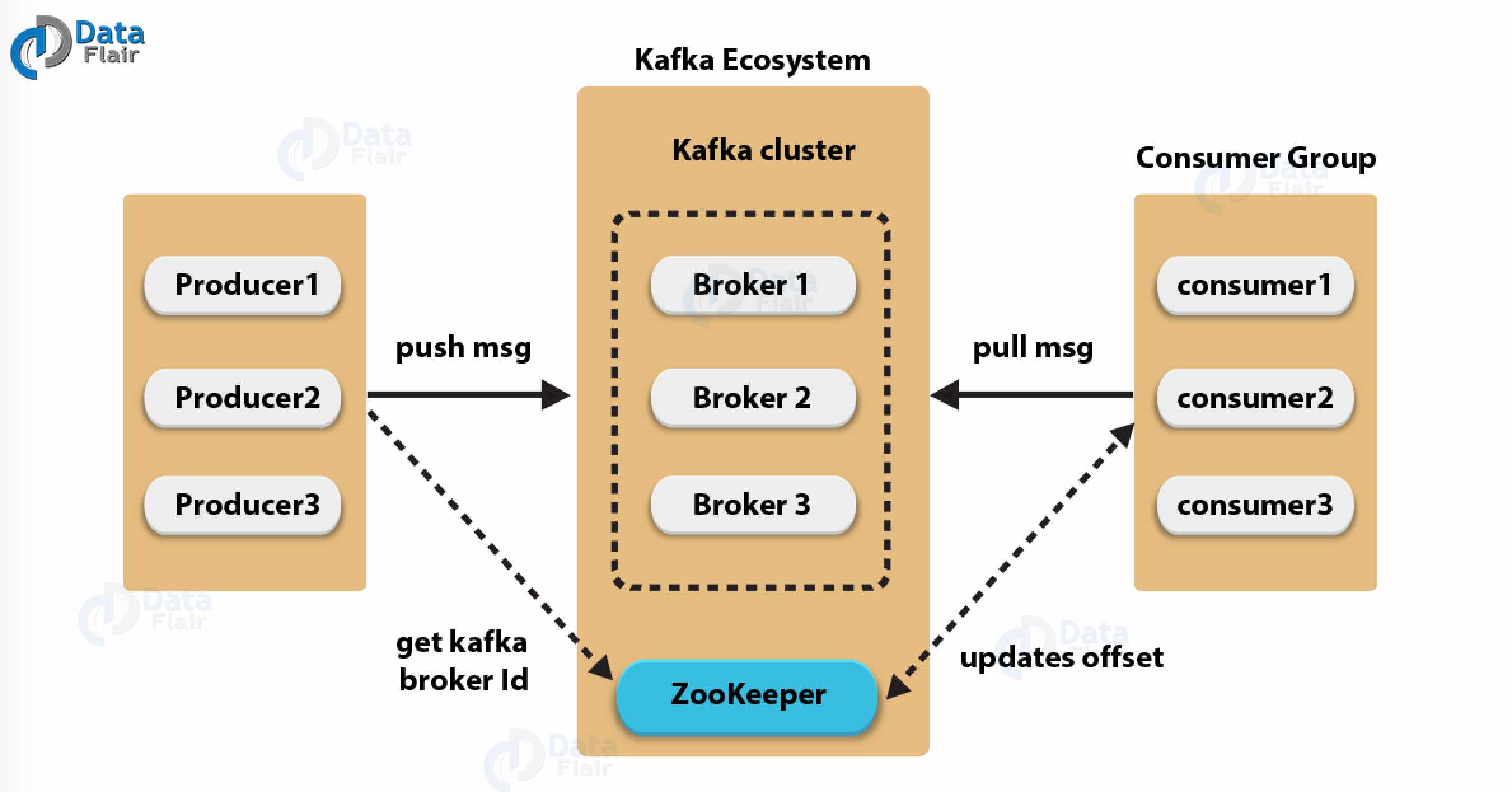 Figure 2. Kafka’s Architecture. (Image source: Data Flair)
Figure 2. Kafka’s Architecture. (Image source: Data Flair)
-
Brokers
A Kafka is a cluster of servers which comprises of many brokers that mainly serve the data and a Zookeeper cluster that stores configuration information. Each broker serves multiple partitions that not necessarily belong to the same topic.
-
Zookeeper
Zookeeper provides configuration maintenance service. What is the configuration? It includes information like what brokers are registered, what are the existing topics, and where are the partitions for each topic. Zookeeper is a fault-tolerant service based on Zab, a consensus algorithm similar to Raft on the high level. Here is a previous post that introduces Raft.
-
Replication
Each partition is replicated according to a replication factor. Each partition has a leader that responds to requests, and other replicas will step up if the leader fails.
 Figure 3. Kafka’s Replication. (Image source: Jack Vanlightly blog)
Figure 3. Kafka’s Replication. (Image source: Jack Vanlightly blog)
Apache Flink
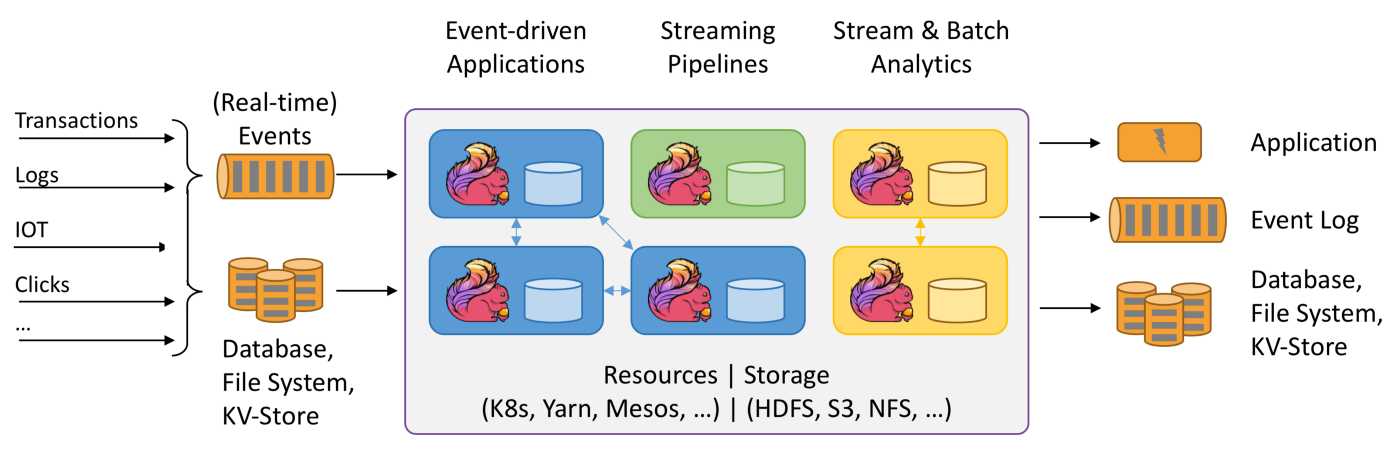 Figure 4. Flink. (Image source: Apache Flink)
Figure 4. Flink. (Image source: Apache Flink)
Besides a switch that manages data flow, we also need a tool that can process the data stream quickly. How quickly? At least as fast as the data production rate. This demand introduces us to Flink which supports the essential data stream transformations such as map, filter, reduce, aggregation, and many more.
Flink’s Architecture
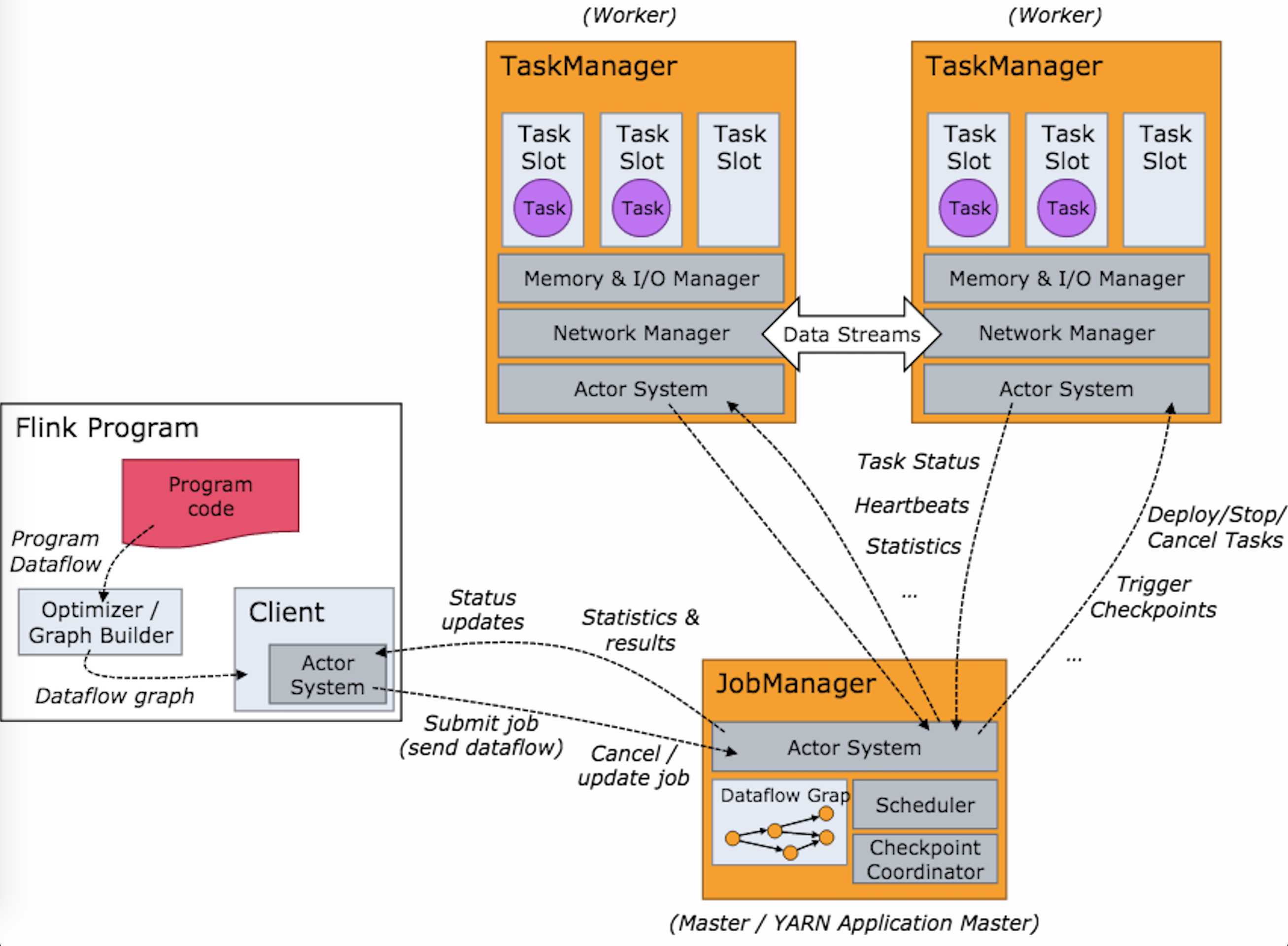 Figure 5. Flink’s Architecture. (Image source: Jark’s Blog)
Figure 5. Flink’s Architecture. (Image source: Jark’s Blog)
A Flink cluster has a JobManager and multiple TaskManagers.
-
Flink Program: The Flink program generates a data-flow diagram, a DAG (directed acyclic graph), based on the program code, and submit the job to the JobManager.
-
JobManager: The JobManager further optimizes the data-flow diagram and splits the job into several tasks. It manages the TaskManagers to complete the tasks.
-
TaskManager: Each TaskManager has several pre-set slots for tasks. Each Task is an independent thread.
Flink’s Dataflow Graph
- Stream Graph: generated based on the initial program code.
- Job Graph: optimized by the Flink Program and submitted to the JobManager.
- Execution Graph: optimized by the JobManager for the actual execution.
 Figure 6. Flink’s Data Flow Diagram. (Image source: Jark’s Blog)
Figure 6. Flink’s Data Flow Diagram. (Image source: Jark’s Blog)
Flink’s Exactly-Once Guarantee
The system fails sometimes so that some messages are processed but not sent out. There are three strategies to deal with this issue:
- At-most-once: Each message is processed at most once, which means messages may be lost.
- At-least-once: Each message is processed at least once, which means messages may be duplicated.
- Exactly-once: Each message is processed exactly once.
The exactly-once grantee is the most desirable but also the hardest and most expensive. For at-most-once, it can be done in a fire-and-forgot fashion without extra implementations. For at-least-once, we need to have an acknowledgment mechanism. For the exactly-once, we need to further avoid duplicates.
Flink manages to achieve the exactly-once guarantee by the Checkpoint mechanism and the barrier aligning mechanism. In short, the data stream is divided into blocks by some barriers. At each operator, data will be kept into a buffer until the block is aligned, i.e. when the whole block has arrived. Then the block will be snapshotted and check-pointed before sending it to the next operator.

Figure 7. Flink’s Checkpoint Mechanism for Exactly-Once. (Image source: Chengxiang Li at Zhihu)
ElasticSearch
Finally, we need to store our data in some database. ElasticSearch is suitable for a search engine application. It allows fast queries to records that include a specific field. For example, we can search for messages that have the phrase “big data”. It provides RESTful API which allows convenient integration into a system.
Inverted Index
An inverted index is an essential idea that allows ElasticSearch to provide search-engine performance. Suppose we have a lot of documents, each having a unique ID. The “non-inverted” index is a mapping from an ID to a document.
| ID | document |
|---|---|
| 0 | hello world |
| 1 | hello ES |
| 2 | ES rules |
The inverted index is a mapping from a string (presenting in a document or multiple documents) to a list of IDs. In this way, when we query a string, the database can return a list of documents that contain the string, just like a search engine. Furthermore, notice that the strings are sorted so that we can use binary search to access the document IDs associated with a string fast. (This means insertion overhead of course.)
| string | IDs |
|---|---|
| ES | [1, 2] |
| hello | [0, 1] |
| rules | [2] |
| world | [0] |
ElasticSearch’s Top-level Concepts
-
index An index in ElasticSearch can be understood as a table in a MySQL database, but of course, the storage structures are very different. We need to specify an index when writing and reading data. We can have an alias to indices to read from multiple indices at once (like searching a query in multiple indices).
-
mapping A mapping is a JSON string that defines the data structure of the documents stored in an index. That being said, the data type is flexible, and there will not be errors if a document does not comply with the mapping. The mapping may seem quite useless in this sense, but it has another more important use: it defines which field will be inverted indexed. Furthermore, for strings, we can define an analyzer to delimit a string, which includes tokenizer and filter which can, for example, filter out stop words. A sample mapping for an index called my-index with 4 fields (“age”, “email”, “employee id”, and “name”) is as follows:
{ "my-index" : { "mappings" : { "properties" : { "age" : { "type" : "integer" }, "email" : { "type" : "keyword" }, "employee-id" : { "type" : "keyword", "index" : false }, "name" : { "type" : "text" } } } } }Both “keyword” and “text” types are strings, but the “keyword” type is treated atomically, while the “text” type can set the analyzer to further be delimited. When “index” is set to false, the field will not be inverted indexed.
Checkout the documentation for more details.
ElasticSearch Storage Structure
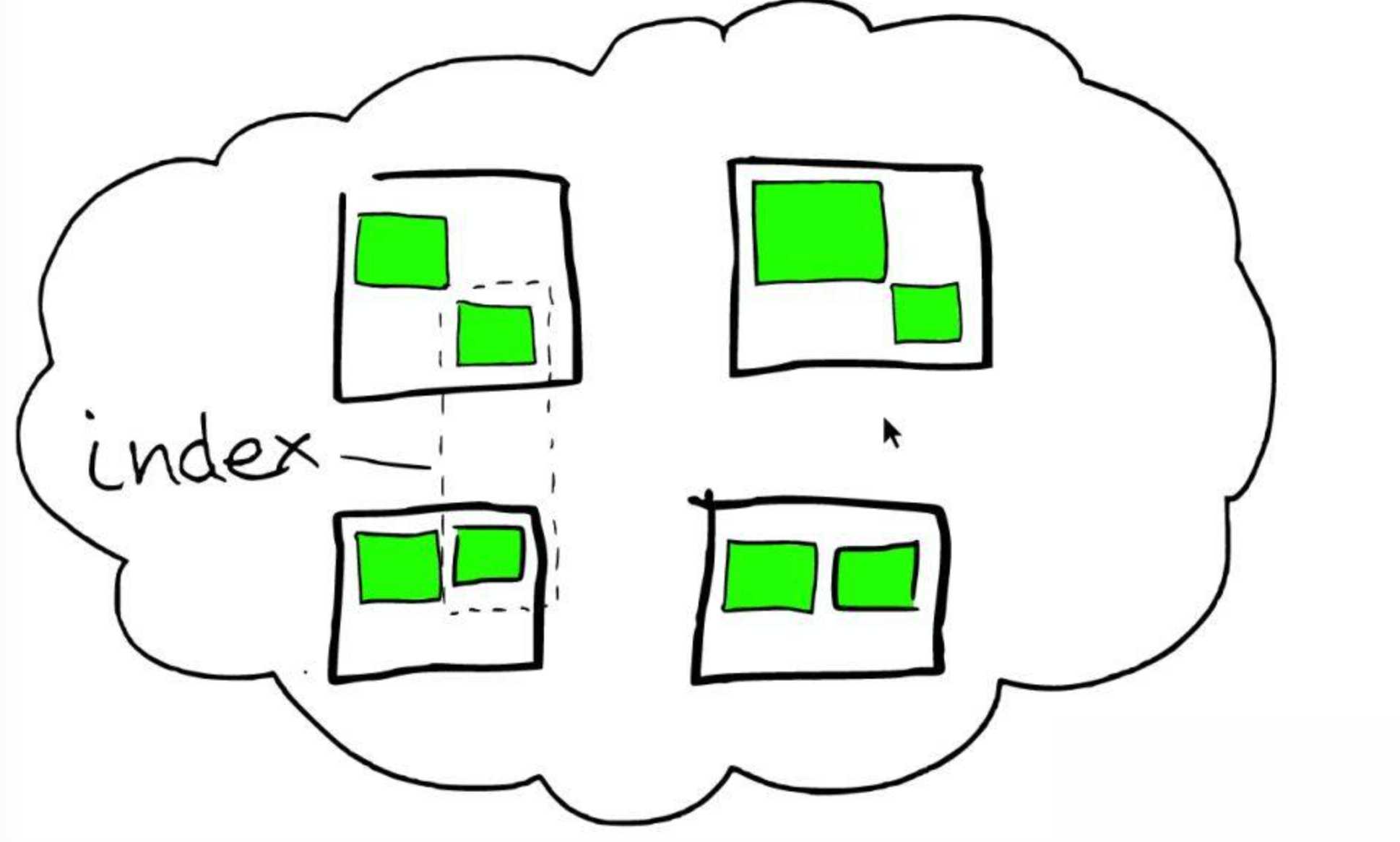 Figure 8. ElasticSearch’s Storage Structure. (Image source: Found)
Figure 8. ElasticSearch’s Storage Structure. (Image source: Found)
- ElasticSearch Cluster: The cluster is represented by the cloud, which consists of several nodes.
- Node: Each node is a server represented by a black box.
- Shard: A shard is a data unit, represented by the green box in the graph. Each index is divided into a preset number of shards. Each node contains several shards. This storage scheme is very similar to Kafka, for which an index is comparable to a Kafka’s topic and a shard is comparable to a Kafka’s partition.
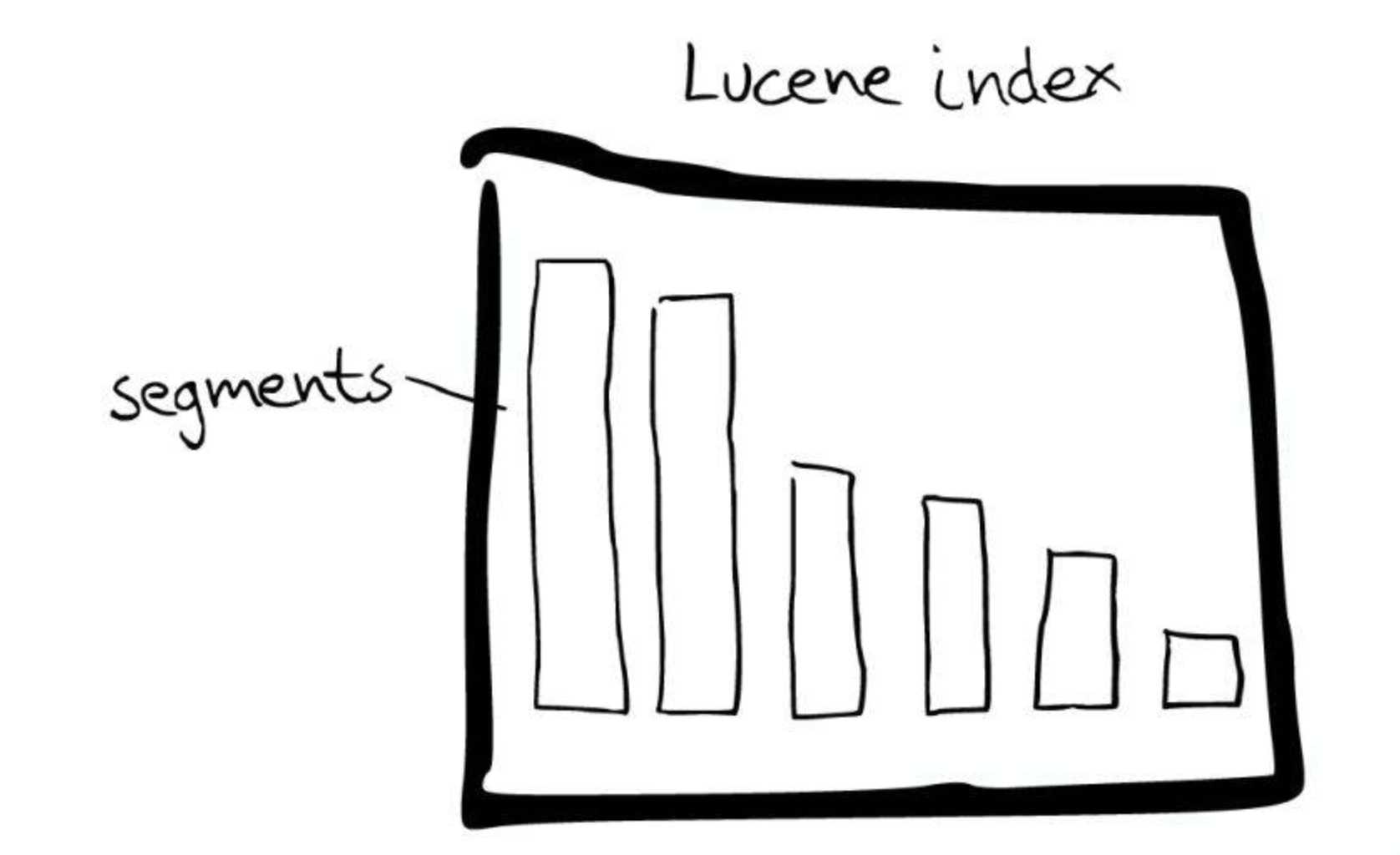 Figure 9. Lucene Index. (Image source: Found)
Figure 9. Lucene Index. (Image source: Found)
What’s inside a shard? ElasticSearch is based on another Apache software—Lucene index, which essentially implements the inverted index. The most relevant structure inside a shard is the Lucene index. A Lucene index is further divided into segments, and in each segment, we have our familiar inverted index.
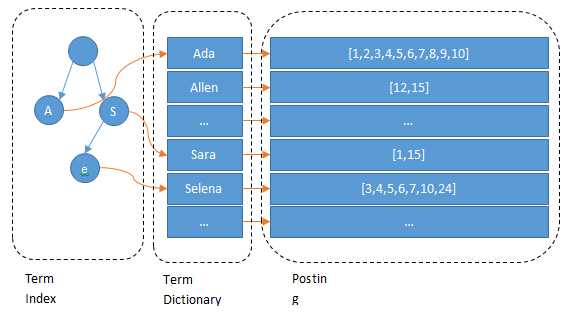
Figure 10. Inverted Index in ElasticSearch. (Image source: Found)
But wait, what is that tree structure on the left? The problem arises when we have too many keys for the inverted index. If you think about it, the number of keys grows much faster than the number of documents. Therefore, we won’t be able to store the entire dictionary in RAM. Even though the binary search is fast, I/O with disks is slow. To facilitate this process, we store the tree structure to point to the exact offset corresponding to a prefix.
The tree structure is officially known as the Finite-State Transducer. If you know about the B+ tree, they have the same high-level idea. Or if you know about the Trie, you should understand how such an implementation can facilitate our queries.
Compression Schemes
The final bit of information, which I think is quite interesting, is two compression schemes used by ElasticSearch. In a search engine setting, the key of an inverted index can point to millions or even billions of document IDs. We, therefore, need some compression scheme to scale down the size. Note that we assume the list is sorted.
The Frame of Reference
 Figure 11. The Frame of Reference Compression Scheme. (Image source: N/A)
Figure 11. The Frame of Reference Compression Scheme. (Image source: N/A)
- delta-encode: with the first value unchanged, every value except the first is substituted by the difference between itself and the previous element.
- split into blocks: each block contains a fixed number of values
- bit packing: the first byte of every block signifies how many bytes each value uses in the block, and the number of bytes is determined by the largest value in the block
Roaring Bitmaps
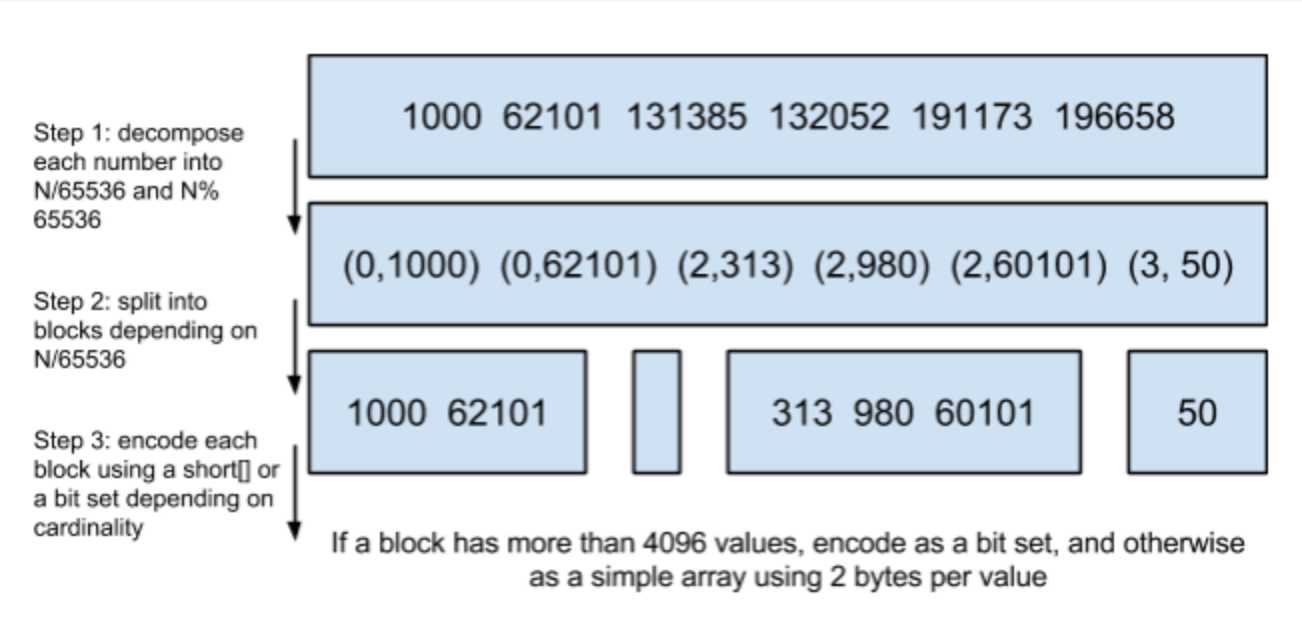 Figure 12. Roaring Bitmaps. (Image source: N/A)
Figure 12. Roaring Bitmaps. (Image source: N/A)
- modulus encode: each value v is encoded into (v/N, v%N), where N is 65536 in the example.
- split into blocks: the encoded values are grouped by v/N
A Java Example
Here is a simple Java example that uses Flink to read from a Kafka server and writes to an ElasticSearch server. Note that you need to start a Kafka server, a Kafka producer, and an ElasticSearch server first.
public class Kafka2ES {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> stream = readFromKafka(env);
writeToElastic(stream);
// execute program
env.execute("Test Flink!");
}
public static DataStream<String> readFromKafka(StreamExecutionEnvironment env) {
Properties properties = new Properties();
// connect to a Kafka server at localhost
properties.setProperty("bootstrap.servers", "localhost:9092");
// consumer group = "test-group"
properties.setProperty("group.id", "test-group");
// create a data stream by consuming Kafka's topic = "test-topic"
FlinkKafkaConsumer<String> flinkKafkaConsumer =
new FlinkKafkaConsumer<>("test-topuc", new SimpleStringSchema(), properties);
// set offset to the earlist
flinkKafkaConsumer.setStartFromEarliest();
// sink data stream to ElasticSearch
DataStream<String> stream = env.addSource(flinkKafkaConsumer);
return stream;
}
public static void writeToElastic(DataStream<String> stream) {
List<HttpHost> httpHosts = new ArrayList<>();
httpHosts.add(new HttpHost("localhost", 9200, "http"));
// create a esSinkBuilder that directly sends each message from the data stream to ES's index = "test-es"
ElasticsearchSink.Builder<String> esSinkBuilder = new ElasticsearchSink.Builder<>(
httpHosts,
new ElasticsearchSinkFunction<String>() {
private IndexRequest createIndexRequest(String element) {
Map<String, String> esJson = new HashMap<>();
esJson.put("message", element);
return Requests
.indexRequest()
.index("test-es")
.source(esJson);
}
@Override
public void process(String s, RuntimeContext runtimeContext, RequestIndexer requestIndexer) {
requestIndexer.add(createIndexRequest(s));
}
}
);
// configuration for the bulk requests; this instructs the sink to emit after every element, otherwise they would be buffered
esSinkBuilder.setBulkFlushMaxActions(1);
stream.addSink(esSinkBuilder.build());
}
}